
参考资料
【追光者系列】HikariCP源码分析之字节码修改类库Javassist委托实现动态代理
SpringBoot 2.0 中默认 HikariCP 数据库连接池原理解析
IConcurrentBagEntry
线程池中包装对象的顶级接口
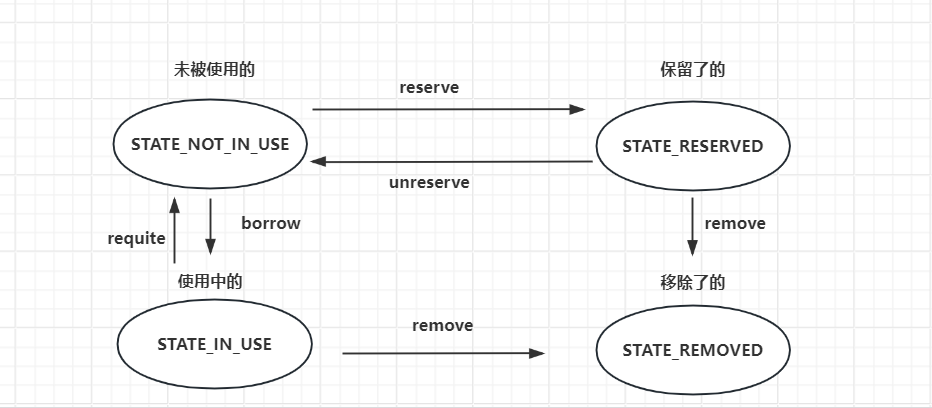
ConcurrentBag
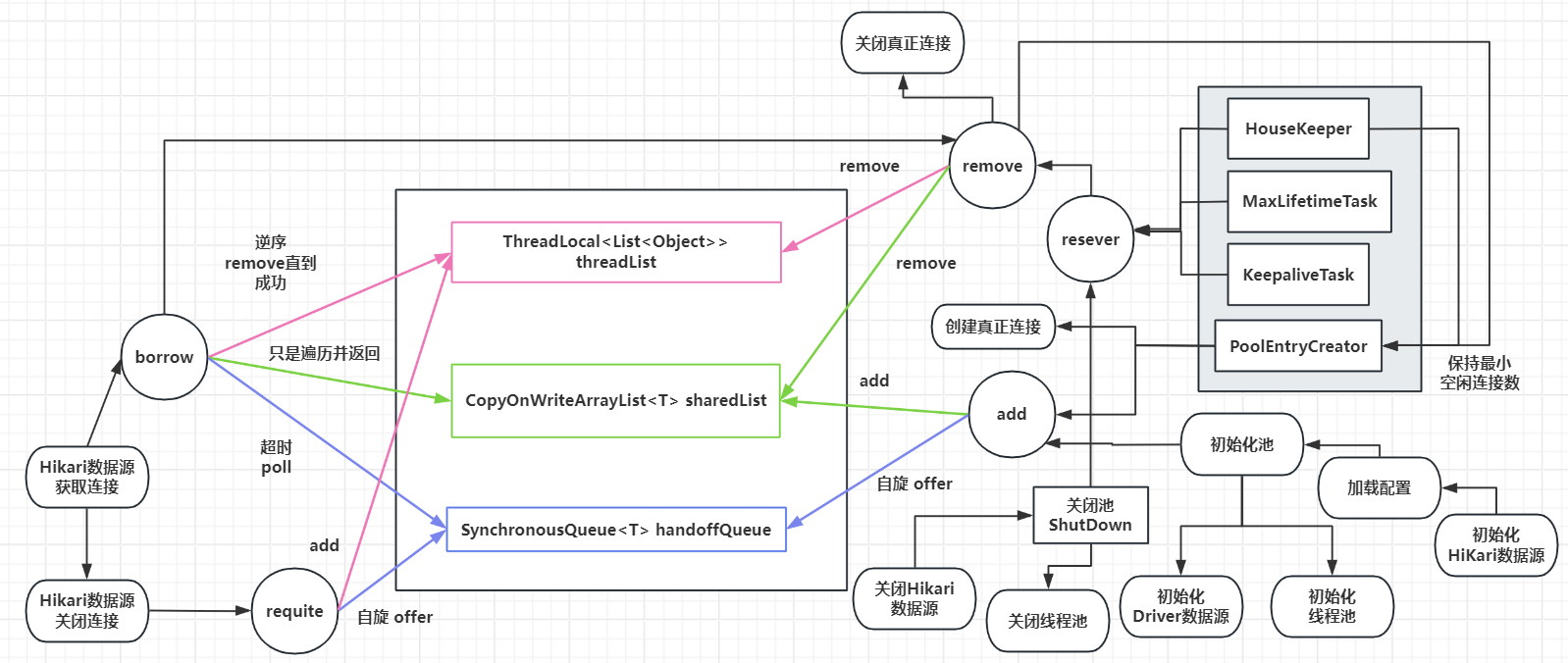
最核心的类,真正的连接池。是一个封装的并发管理工具,负责管理池化资源,不仅仅是数据库连接,其他池化资源都可以通过它来管理。它是一个 lock-free 集合,在连接池(多线程数据交互)的实现上具有比 LinkedBlockingQueue 和 LinkedTransferQueue 更优越的并发读写性能。
注意:ConcurrentBag 中通过 borrow 方法进行数据资源借用,通过 requite 方法进行资源回收,注意其中 borrow 方法只提供对象引用,不移除对象。所以从 bag 中“借用”的 items 实际上并没有从任何集合中删除,因此即使引用废弃了,垃圾收集也不会发生。因此使用时 通过 borrow 取出的对象必须通过 requite 方法进行放回,否则会导致内存泄露,只有"remove"方法才能完全从 bag 中删除一个对象。
// 通过泛型要求其包含的池化资源必须实现 IConcurrentBagEntry 接口
ConcurrentBag<T extends IConcurrentBagEntry> implements AutoCloseable
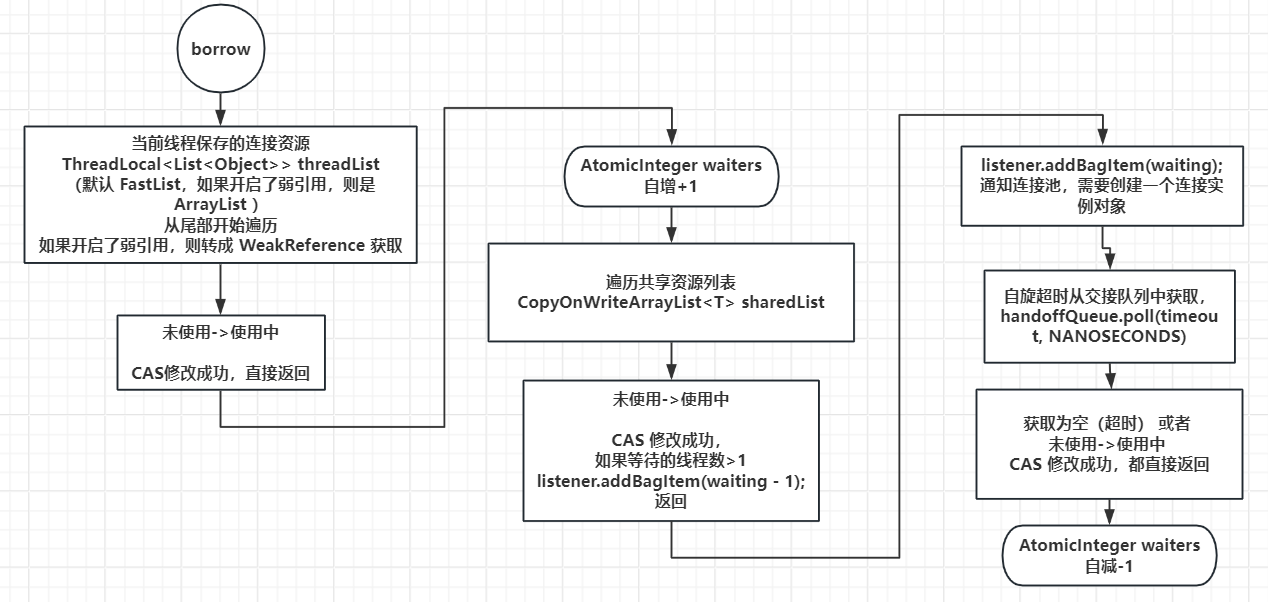
T borrow(long timeout, final TimeUnit timeUnit)
boolean reserve(final T bagEntry)
//将当前资源的状态设置为保留状态让其线程不能借用,可以做一些逻辑操作
return bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_RESERVED);
void unreserve(final T bagEntry)
//将当前资源的状态设置为未使用状态,让其它线程可以借用
if (bagEntry.compareAndSet(STATE_RESERVED, STATE_NOT_IN_USE)) {
//判断是否有线程在等待资源的获取
while (waiters.get() > 0 && !handoffQueue.offer(bagEntry)) {
Thread.yield();
}
}
void add(final T bagEntry)
// 判断连接池是否已经关闭
if (closed) {打日志、抛异常}
// 直接将资源对象放入到共享的资源列表中
sharedList.add(bagEntry);
// 判断当前是否有等待连接资源的线程,判断当前创建的连接资源是否可以被使用,然后将资源方式交接队列中,如果失败了,那么就需要进行自旋操作
while (waiters.get() > 0 &&bagEntry.getState() == STATE_NOT_IN_USE && !handoffQueue.offer(bagEntry)) {
Thread.yield();
}
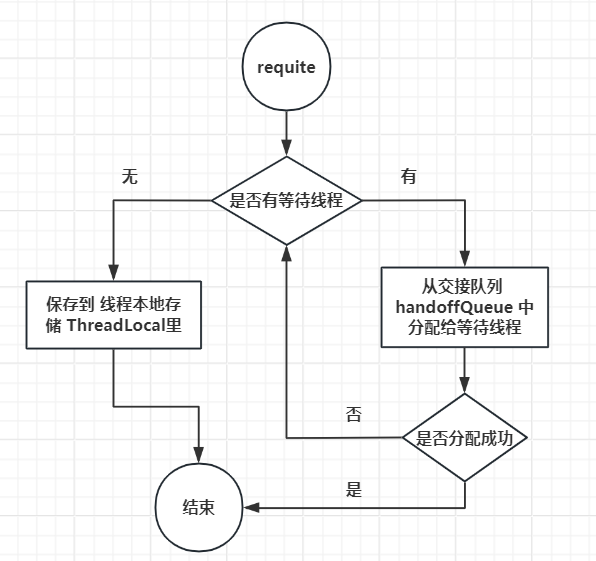
void requite(final T bagEntry)
// 归还连接资源
//先将资源的状态设置为未使用
bagEntry.setState(STATE_NOT_IN_USE);
//判断当前是否还有线程在等待资源的获取,如果有正在等待的线程,那么直接将资源放入交接队列中
for (int i = 0; waiters.get() > 0; i++) {
// 如果当前资源为未使用状态,那么直接放入交接队列中;如果是其它的状态直接返回
// offer 返回为 true说明有其他线程消费了, state 可能不为 STATE_NOT_IN_USE 了, 直接结束
if (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {
return;
}else if ((i & 0xff) == 0xff) { //如果当前遍历的数为255还有线程在等待获取,那么就休眠10微秒
parkNanos(MICROSECONDS.toNanos(10));
}else {
//否则就通知cpu让出当前线程的执行权,等其它的高优先级的线程执行完毕后再执行
Thread.yield();
}
}
//如果没有正在获取的线程,那么直接将资源放入当前线程的资源列表中
final List<Object> threadLocalList = threadList.get();
//如果当前线程的资源列表超过了50个了,就不需要当前实例资源了,等待销毁即可
if (threadLocalList.size() < 50) {
//将资源添加到本地线程的资源列表中
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) : bagEntry);
}
boolean remove(final T bagEntry)
//判断当前资源的状态是否为使用中或者预留中
if (!bagEntry.compareAndSet(STATE_IN_USE, STATE_REMOVED) && !bagEntry.compareAndSet(STATE_RESERVED, STATE_REMOVED) && !closed) {
LOGGER.warn(...);
return false;
}
//将资源从共享列表中移除
final boolean removed = sharedList.remove(bagEntry);
if (!removed && !closed) {
LOGGER.warn(...);
}
//从本地资源表中移除
threadList.get().remove(bagEntry);
return removed;borrow
采用了 queue-stealing 的机制获取元素:首先尝试从 ThreadLocal 中获取属于当前线程的元素来避免锁竞争,如果没有可用元素则再从共享的 CopyOnWriteArrayList 中获取。此外,ThreadLocal 和 CopyOnWriteArrayList 在 ConcurrentBag 中都是成员变量,线程间不共享,避免了伪共享(false sharing)的发生。同时因为线程本地存储中的连接是可以被其他线程窃取的,在共享队列中获取空闲连接,所以需要用 CAS 方法防止重复分配。
requite
首先将数据库连接状态改为未使用,之后查看是否存在等待线程,如果有则分配给等待线程;否则将该数据库连接保存到线程本地存储里。
总流程
PoolEntry
PoolEntry
AtomicIntegerFieldUpdater<PoolEntry> stateUpdater;
volatile int state = 0;
boolean compareAndSet(int expect, int update)
void setState(int update)
Connection createProxyConnection()
return ProxyFactory.getProxyConnection(this, connection, ..);
// Body is replaced (injected) by JavassistProxyFactory
throw new IllegalStateException("You need to run the CLI build ");
void recycle()JavassistProxyFactory
利用 javassist 生成代理类:
生成 HikariProxyConnection、HikariProxyStatement、HikariProxyCallableStatement、HikariProxyPreparedStatement、HikariProxyResultSet、HikariProxyDatabaseMetaData
generateProxyClass(Connection.class, ProxyConnection.class.getName(), methodBody);
generateProxyClass(Statement.class, ProxyStatement.class.getName(), methodBody);
generateProxyClass(ResultSet.class, ProxyResultSet.class.getName(), methodBody);
generateProxyClass(DatabaseMetaData.class, ProxyDatabaseMetaData.class.getName(), methodBody);
generateProxyClass(PreparedStatement.class, ProxyPreparedStatement.class.getName(), methodBody);
generateProxyClass(CallableStatement.class, ProxyCallableStatement.class.getName(), methodBody);对 ProxyFactory 进行实现:modifyProxyFactory()
执行前:
ProxyConnection getProxyConnection
Statement getProxyStatement
CallableStatement getProxyCallableStatement
PreparedStatement getProxyPreparedStatement
ResultSet getProxyResultSet
DatabaseMetaData getProxyDatabaseMetaData
throw new IllegalStateException("You need to run the CLI build and you need target/classes in your classpath to run.");执行后:
ProxyConnection getProxyConnection => new (HikariProxyConnection)
Statement getProxyStatement => new (HikariProxyStatement)
CallableStatement getProxyCallableStatement => new (HikariProxyCallableStatement)
PreparedStatement getProxyPreparedStatement => new (HikariProxyPreparedStatement)
ResultSet getProxyResultSet => new (HikariProxyResultSet)
DatabaseMetaData getProxyDatabaseMetaData => new (HikariProxyDatabaseMetaData)HikariPool
管理连接池
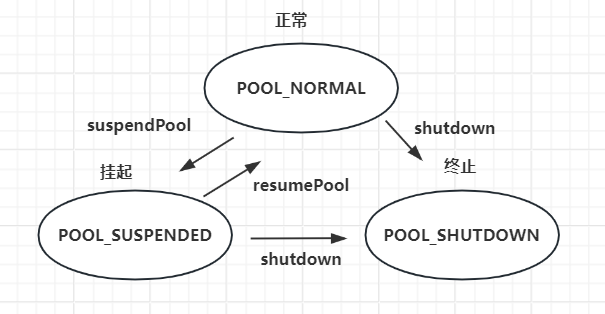
HikariPool
Connection getConnection()
return getConnection(connectionTimeout);
Connection getConnection(final long hardTimeout)
// 加锁(用于挂起线程池的锁,默认不挂起为空操作,信号量实现)
suspendResumeLock.acquire();
超时自旋
do {
// 从池中获取连接资源
PoolEntry poolEntry = connectionBag.borrow(timeout, MILLISECONDS);
if (...) {
closeConnection(...);
timeout = hardTimeout - elapsedMillis(startTime);
}else{
metricsTracker.recordBorrowStats(poolEntry, startTime);
// 根据连接实例创建一个代理连接对象,并且启动一个定时任务监测连接是否泄露
return poolEntry.createProxyConnection(leakTaskFactory.schedule(poolEntry), now);
}
}while(timeout > 0L)
// 解锁
suspendResumeLock.release();
boolean softEvictConnection()
poolEntry.markEvicted();
if (owner || connectionBag.reserve(poolEntry)) {
closeConnection(poolEntry, reason);
return true;
}
return false;
void addBagItem(final int waiting)
//传递进来的等待线程的数量减去连接队列数量 大于等于0
final boolean shouldAdd = waiting - addConnectionQueueReadOnlyView.size() >= 0;
if (shouldAdd) {
addConnectionExecutor.submit(poolEntryCreator);
}HikariConfig
maxLifetime
连接最大生命周期,默认为 30 min,单位 ms
如果 不为 0 且小于 30 s 则会设为 30 min。强烈建议设置这个参数。
大于 0 才生效。
mysql
wait_timeout的作用:为了防止空闲连接浪费,占用资源,在超过 wait_timeout 时间后,会主动关闭该连接,清理资源。通过
show variables like 'wait_timeout%'查看,默认是 28800 s,也就是 8 小时。hikaricp 如何知道池子里维护的一把连接,有没有被 mysql 回收呢?
hikaricp 的兜底:在空闲连接超过 maxLifetime,就会从连接池中剔除,防止业务进程取到了已关闭的连接,导致业务受损。
建议:设置比数据库超时时长少 30 秒。
keepaliveTime & connectionTestQuery
检测连接存活间隔时间,默认为 0,单位 ms
如果 不为 0 且小于 30 s 则会重置为 0。
如果 maxLifetime、keepaliveTime 都大于 0 ,且 keepaliveTime 大于等于 maxLifetime,则会重置为 0。
大于 0 才生效。
每隔
keepaliveTime时间间隔,去和数据库发送心跳,来探测连接是否有效。如果发现是无效的,就会及时从连接池中剔除,来保证业务进程获取到的都是有效连接。如果配置了
connectionTestQuery,如 "select 1",心跳检查过程就会调用connectionTestQuery(需要配置keepaliveTime,其默认为 0,不然没用)而
connectionTestQuery配置项,官方建议如果驱动支持 JDBC4,不要设置此属性!因为相比于通过 select 查询方式,mysql 自带的 ping 命令(目测应该就是 TCP 的 ping ),性能更高(直接在 mysql server 返回结果,就不会做语法解析,执行优化,再通过存储引擎操作)
maximumPoolSize —— maxPoolSize
最大连接数,其实就是线程池中队列的大小。默认大小为 10
minimumIdle —— minIdle
最小空闲连接数,默认为 10
如果小于 0 或者超过 maximumPoolSize,则设成 maximumPoolSize(默认情况,此时 idleTimeout 参数不生效)。
idleTimeout
连接允许最长空闲时间,默认 10 min,单位 ms
如果 idleTimeout + 1 s > maxLifetime 且 maxLifetime > 0,则会被设为 0;
如果 idleTimeout != 0 且小于 10 s,则会被重置为 10 min。
大于 0 且 minimumIdle < maximumPoolSize 时,这个参数才生效,当空闲连接数超过 minimumIdle,而且空闲时间超过 idleTimeout,则连接会被移除。
connectionTimeout
获取连接超时时间,默认 30 s,单位 ms
如果为 0 则被设置为 Integer.MAX_VALUE,如果 小于 250 ms,重置为 30 s(或抛异常);
超过这个时长还没可用的连接则发生 SQLException。
validationTimeout
验证连接有效性超时时间,默认 5 s,单位 ms
如果 小于 250 ms,重置为 5 s(或抛异常);
initializationFailTimeout
初始化时检查失败超时时间,默认 1 ms,单位 ms
初始化连接池时检查快速失败,大于等于 0 生效,尝试创建一个连接(直接创建,而不是通过线程池去创建)。
leakDetectionThreshold
连接泄露检测阈值,默认为 0,单位 ms
大于 0 才生效,配置小于 2000 ms 或 大于 maxLifetime 会被重置为 0。
HikariDataSource
HikariDataSource
Connection getConnection()
if (fastPathPool != null) {
return fastPathPool.getConnection();
}
HikariPool result = pool;
if (result == null) {
synchronized(this){
pool = result = new HikariPool(this);
this.seal();
}
}
return result.getConnection();线程池
ScheduledExecutorService houseKeepingExecutorServicenew ScheduledThreadPoolExecutor(1, threadFactory, new ThreadPoolExecutor.DiscardPolicy());
定时执行 ProxyLeakTaskFactory 提交连接泄漏检测的任务(获取到连接时开始,延迟
leakDetectionThresholdms 后执行)定时执行 HouseKeeper 任务(初始化 HikariPool 时开始,延迟 100 ms 后执行,且按间隔时间
housekeepingPeriodMs【默认 30 s】执行)定时执行 MaxLifetimeTask 任务(创建连接对象 PoolEntry 时开始,延迟
maxLifetimems 【有随机偏移量】后执行)定时执行 KeepaliveTask 任务(创建连接对象 PoolEntry 时开始,延迟
keepaliveTimems 【有随机偏移量】后执行,且按间隔时间 keepaliveTime 执行)
ThreadPoolExecutor addConnectionExecutor:调用 IBagStateListener 实例 HikariPool 的方法 addBagItem(final int waiting) 进行添加连接实例时 ,提交 PoolEntryCreator 任务底层阻塞队列使用的是 LinkedBlockingQueue(maxPoolSize), new ThreadPoolExecutor(1, 1 , 5 , SECONDS, queue, threadFactory, new ThreadPoolExecutor.DiscardOldestPolicy());
ThreadPoolExecutor closeConnectionExecutor:关闭某个连接对象 PoolEntry 时执行任务底层阻塞队列使用的是 LinkedBlockingQueue(maxPoolSize), new ThreadPoolExecutor(1, 1 , 5 , SECONDS, queue, threadFactory, new ThreadPoolExecutor.CallerRunsPolicy());
closeConnectionExecutor.execute(() -> { quietlyCloseConnection(connection, closureReason); if (poolState == POOL_NORMAL) { // 填充到最小空闲连接 fillPool(); } }); fillPool() // 填充的连接个数:min(最大连接数与总连接数差值,最小空闲连接数与空闲连接数差值) - 连接创建等待任务数 int connectionsToAdd = Math.min(config.getMaximumPoolSize() - getTotalConnections(), config.getMinimumIdle() - getIdleConnections()) - addConnectionQueueReadOnlyView.size(); for (int i = 0; i < connectionsToAdd; i++) { // 提交一个连接创建的任务 addConnectionExecutor.submit((i < connectionsToAdd - 1) ? poolEntryCreator : postFillPoolEntryCreator); }
线程任务
HikariPool.HouseKeeper implements Runnable 关闭多余的超时空闲连接,填充连接以保持最小的空闲连接【fillPool()】
run()
HikariPool.MaxLifetimeTask implements Runnable 兜底,超过最大生命周期则关闭
run()
HikariPool.KeepaliveTask implements Runnable 连接状态周期性检测,通过connectionTestQuery,如果连接不活跃了则关闭重新创建一个
run()
ProxyLeakTask implements Runnable 连接泄漏检测,如果连接在 leakDetectionThreshold 的时间还没关闭,则打日志警告
run()
HikariPool.PoolEntryCreator implements Callable<Boolean> 创建连接对象 PoolEntry并添加到 ConcurrentBag集合
FastList:保存打开的 Statement,当 Statement 关闭或 Connection 关闭时需要将对应的 Statement 从 List 中 移除。通常情况下,同一个 Connection 创建了多个 Statement 时,后打开的 Statement 会先关闭避免每次 get() 调用都要进行 range check,避免调用 remove() 时的从头到尾的扫描。
CopyOnWriteArrayList:存放共享资源数据,写时复制,线程安全,实现了读写分离、最终一致,在读多写少场景下高性能。
JUC
CAS、AtomicIntegerFieldUpdater: IConcurrentBagEntry 针对四个状态,调用 compareAndSet
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) { } PoolEntry implements IConcurrentBagEntry private volatile int state = 0; private static final AtomicIntegerFieldUpdater<PoolEntry> stateUpdater = AtomicIntegerFieldUpdater.newUpdater(PoolEntry.class, "state"); boolean compareAndSet(int expect, int update) return stateUpdater.compareAndSet(this, expect, update);
注意:使用 AtomicIntegerFieldUpdater 代替 AtomicInteger 的好处:减小 PoolEntry 对象内存开销
自旋:超时退出、让步、睡眠
do { final long start = currentTime(); ... //减去当前消耗的时间 timeout -= elapsedNanos(start); } while (timeout > 10_000); while (waiters.get() > 0 && !handoffQueue.offer(bagEntry)) { Thread.yield(); } for (int i = 0; waiters.get() > 0; i++) { if (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) { return; } else if ((i & 0xff) == 0xff) { parkNanos(MICROSECONDS.toNanos(10)); } else { Thread.yield(); } }Semaphore: SuspendResumeLock
获取连接时,用于挂起连接池的锁,默认不挂起——为空操作的锁 FAUX_LOCK new Semaphore(10000, true),公平锁,先进先出 加锁 if (acquisitionSemaphore.tryAcquire()) { return; } else if (Boolean.getBoolean("com.zaxxer.hikari.throwIfSuspended")) { 抛异常 } acquisitionSemaphore.acquireUninterruptibly(); 解锁 acquisitionSemaphore.release();CopyOnWriteArrayList: ConcurrentBag 中的 sharedList,共享资源数据
SynchronousQueue: ConcurrentBag 中的 handoffQueue,交接队列,线程池会将连接器对象存储到当前队列中
使用了非阻塞的 offer,将指定的元素插入此队列中,如果另一个线程正在等待接收它,则立即将其移交给该线程,并返回 true,否则立即返回 false。 使用了超时阻塞的 poll,在放弃之前等待一段时间,以看是否有生产者线程能够提供元素。LinkedBlockingQueue:作为 HikariPool 中执行创建连接任务的线程池 addConnectionExecutor 、执行关闭连接任务的线程池 closeConnectionExecutor 的阻塞队列,核心线程数和最大线程数都为 1,队列大小为 最大连接数 maxPoolSize
ThreadLocalRandom: HikariPool#createPoolEntry(),针对最大生命周期、活跃检测周期,计算随机偏移除时间,引入随机性以减少并发操作的规律性,使用 ThreadLocalRandom 而非 Random 是因为 ThreadLocalRandom 是线程局部的,每个线程有自己的实例,避免了多线程间竞争锁的开销,对于高并发场景更为高效。
//获取到最大生命周期 final long maxLifetime = config.getMaxLifetime(); final long variance = maxLifetime > 10_000 ? ThreadLocalRandom.current().nextLong(maxLifetime / 40):0; final long lifetime = maxLifetime - variance; //设置一个houseKeepingExecutorService的定时任务用于检查连接的最大生命周期 poolEntry.setFutureEol(houseKeepingExecutorService.schedule(new MaxLifetimeTask(poolEntry), lifetime, MILLISECONDS)); //设置活跃检测周期 final long keepaliveTime = config.getKeepaliveTime(); // variance up to 10% of the heartbeat time final long variance = ThreadLocalRandom.current().nextLong(keepaliveTime / 10); final long heartbeatTime = keepaliveTime - variance; //设置定时任务来检查连接是否活跃,如果连接不活跃了那么会再创建一个新的线程 poolEntry.setKeepalive(houseKeepingExecutorService.scheduleWithFixedDelay(new KeepaliveTask(poolEntry), heartbeatTime, heartbeatTime, MILLISECONDS));
问题
https://blog.csdn.net/lijun0302/article/details/107658247
https://blog.csdn.net/IamOceanKing/article/details/82698738
连接长时间处于空闲状态,也不会被释放,那新的连接请求不能直接使用它吗?
这些连接实际已是失效连接,如果 maxLifetime 设置得过长,且没有合理的 idleTimeout 机制来回收空闲连接,可能引发问题。即使连接池中有空闲连接,但它们因长时间未被使用而变得不再有效(例如,数据库服务器端可能因为超时长无活动而关闭了这些连接),新的请求尝试复用这些连接时可能会遇到失败,表现为连接不可用或错误,而不是成功复用。
maxLifetime 设置的比数据库 wait_timeout 小了,还有必要设置 idleTimeout 并让其生效吗?
maxLifetime 只是针对每个连接的最大生命周期,设置的过大不行,过小也不行,这样违背了池化的初衷,只是个兜底,无法精确控制空闲连接数范围。
而 idleTimeout 生效的话,通过 minimumIdle 可以关闭多余的空闲连接。
连接数、配置
连接数
https://cloud.tencent.com/developer/article/1625627
https://cloud.tencent.com/developer/article/1689884
连接数不是越大越好?
要知道,即使是单核 CPU 的计算机也能“同时”运行着数百个线程。但我们其实都知道,这只不过是操作系统快速切换时间片,跟我们玩的一个小把戏罢了。
一核 CPU同一时刻只能执行一个线程,然后操作系统切换上下文,CPU 核心快速调度,执行另一个线程的代码,不停反复,给我们造成了所有进程同时运行假象。
其实,在一核 CPU 的机器上,顺序执行 A 和 B 永远比通过时间分片切换“同时”执行A和B要快,一旦线程的数量超过了 CPU 核心的数量,再增加线程数系统就只会更慢,而不是更快,因为这里涉及到上下文切换耗费的额外的性能。
最佳实践
推荐的公式:
connections = ((core_count * 2) + effective_spindle_count)【连接数 = ((核心数 * 2) + 有效磁盘数)】
core_count:不是“超线程”技术之后看到的核心数,而是实际的核心数。
effective_spindle_count:如果数据可以完全 cache 到内存则取 0,否则随着 cache 命中率降低,则这个数值会变高。
MySQL 方面,可以认为是 innodb_buffer_pool 的命中率。
配置
https://www.cnblogs.com/coderaniu/p/15185579.html
默认
# 30 min
maxLifetime=1800000
keepaliveTime=0
maximumPoolSize=10
minimumIdle=10
# 10 min,注意需要 minimumIdle < maximumPoolSize 才生效
idleTimeout=600000
# 30s
connectionTimeout=30000
validationTimeout=5000
leakDetectionThreshold=0针对预编译的配置
https://qsli.github.io/2020/05/05/cache-prep-stmts/
以下是针对 MYSQL 驱动的配置参数:
# 在每个连接中缓存的语句的数量。默认值为保守值25。建议将其设置为250-500之间
dataSource.prepStmtCacheSize=300
# 缓存的已准备SQL语句的最大长度,默认值是256,但是往往这个长度不够用
dataSource.prepStmtCacheSqlLimit=2048
# 缓存开关,如果这里设置为false,上面两个参数都不生效,默认 false
dataSource.cachePrepStmts=true
#较新版本的 MySQL 支持服务器端准备好的语句,这可以提供实质性的性能提升,默认 false
dataSource.useServerPrepStmts=true注意:对应 yml 中 配置的是 spring.datasource.hikari.dataSourceProperties.xxx
MySQL
-- 空闲连接超时时间 28800 s = 8 h
SHOW VARIABLES LIKE 'wait_timeout%';
-- 最大连接数 200
SHOW VARIABLES LIKE '%max_connections%';
-- 当前线程列表
SHOW PROCESSLIST;
-- 当前线程列表,info列展示完整sql
SHOW FULL PROCESSLIST;
-- 当前的线程信息
SHOW STATUS LIKE 'Threads%';
1. Threads_connected:当前打开的连接数,表示与MySQL服务器建立连接的客户端数量。
2. Threads_running:当前正在运行的线程数,即正在执行查询或正在处理请求的线程。
3. Threads_created:自服务器启动以来创建的线程总数,反映了连接创建的频率。
4. Threads_cached:线程缓存中缓存的线程数,某些连接池实现中表示可以重用的空闲连接。
-- 连接统计
SHOW STATUS LIKE '%Connection%';
自数据库上次启动以来 = 历史
1.Connections:历史尝试连接MySQL服务器的次数,包括成功的和失败的连接尝试。
2.Max_used_connections:历史同时存在的最大连接数的峰值。
3.Max_used_connections_time:达到Max_used_connections时的